@ai呀蔡蔡2025年DeepSeek自学手册-从理论模型训练到实践模型应用73页



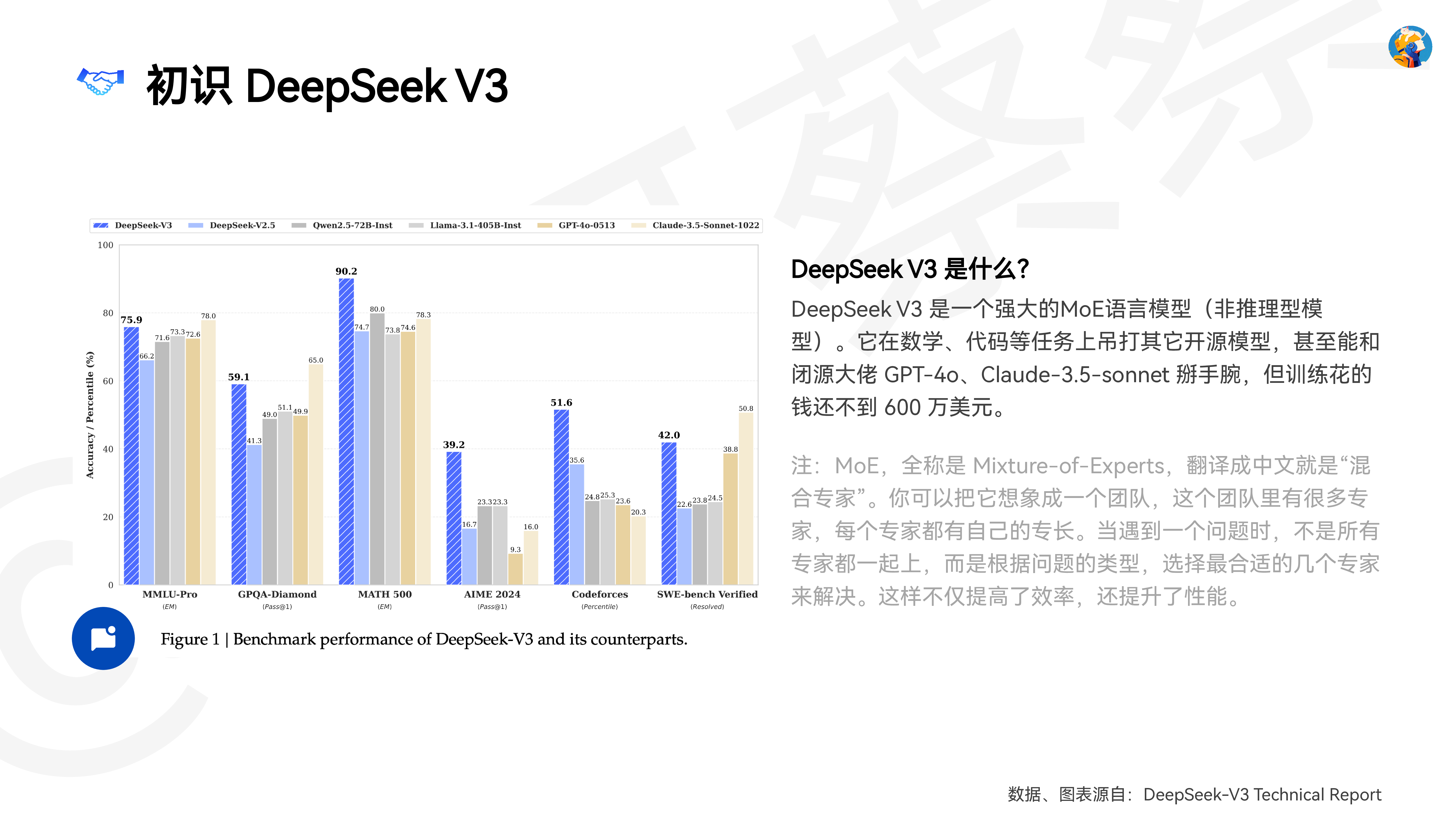
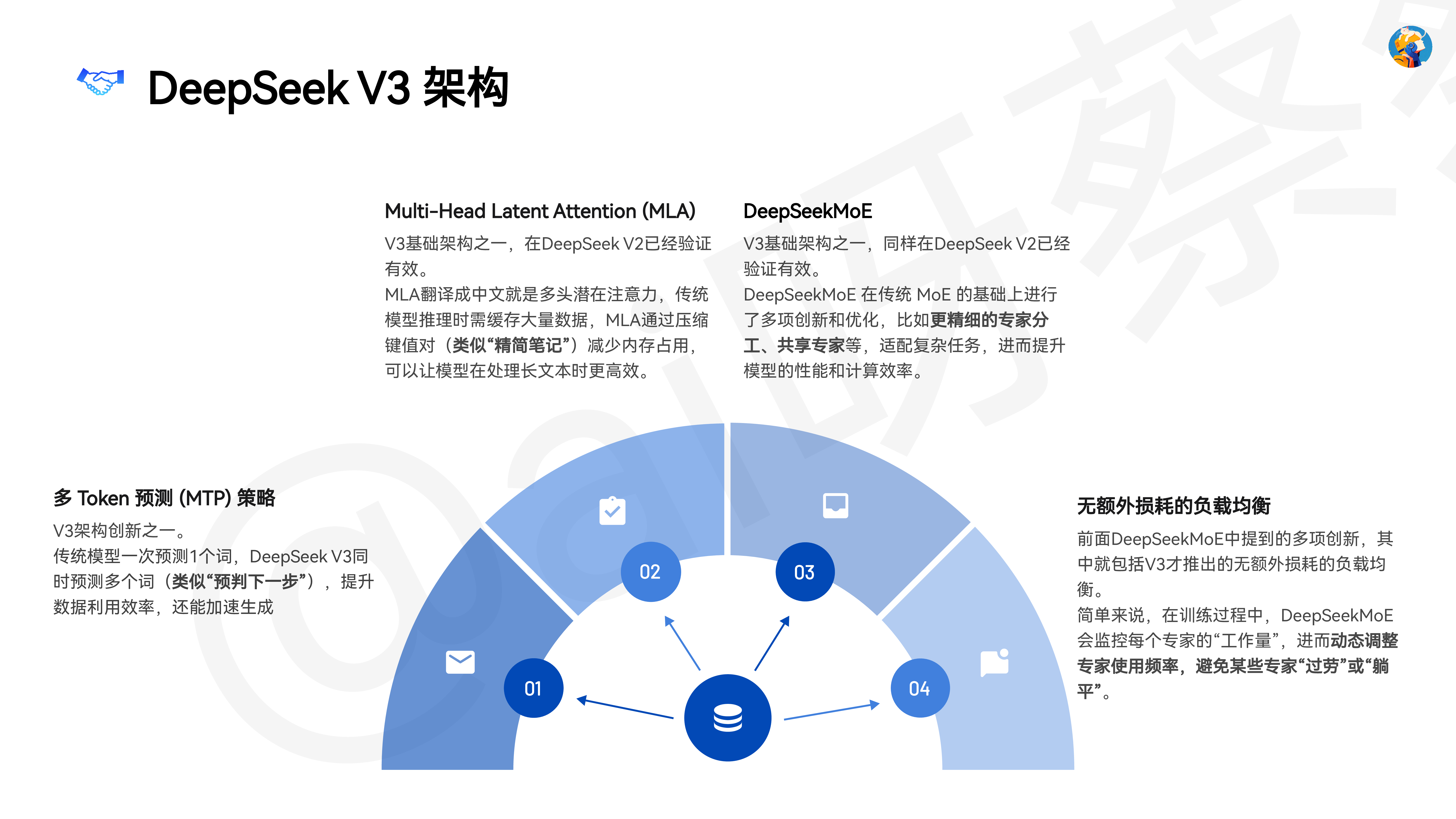

DeepSeek自学手册从理论(模型训练)到实践(模型应用)作者:@ai呀蔡蔡(全平台同名)0104020503DeepSeek V3和R1是怎么训练出来的13个DeepSeek官方提示词样例DeepSeek R1后提示词的变与不变DeepSeek实际应用场景DeepSeek R1四大使用技巧Contents目录06DeepSeek替代方案(在线&本地部署)注:当前手册的信息更新截至2025年2月10日01DeepSeek V3 和 R1是怎么训练出来的@ai呀蔡蔡DeepSeek V3 是什么?DeepSeek V3 是一个强大的MoE语言模型(非推理型模型)。它在数学、代码等任务上吊打其它开源模型,甚至能和闭源大佬 GPT-4o、Claude-3.5-sonnet 掰手腕,但训练花的钱还不到 600 万美元。注:MoE,全称是 Mixture-of-Expe�s,翻译成中文就是“混合专家”。你可以把它想象成一个团队,这个团队里有很多专家,每个专家都有自己的专长。当遇到一个问题时,不是所有专家都一起上,而是根据问题的类型,选择最合适的几个专家来解决。这样不仅提高了效率,还提升了性能。初识 DeepSeek V3数据、图表源自:DeepSeek-V3 Technical Repo�@ai呀蔡蔡DeepSeek V3 架构多 Token 预测 (MTP) 策略V3架构创新之一。传统模型一次预测1个词,DeepSeek V3同时预测多个词(类似“预判下一步”),提升数据利用效率,还能加速生成Multi-Head Latent Attention (MLA)V3基础架构之一,在DeepSeek V2已经验证有效。MLA翻译成中文就是多头潜在注意力,传统模型推理时需缓存大量数据,MLA通过压缩键值对(类似“精简笔记”)减少内存占用,可以让模型在处理长文本时更高效。DeepSeekMoEV3基础架构之一,同样在DeepSeek V2已经验证有效。DeepSeekMoE 在传统 MoE 的基础上进行了多项创新和优化,比如更精细的专家分工、共享专家等,适配复杂任务,进而提升模型的性能和计算效率。无额外损耗的负载均衡前面DeepSeekMoE中提到的多项创新,其中就包括V3才推出的无额外损耗的负载均衡。简单来说,在训练过程中,DeepSeekMoE 会监控每个专家的“工作量”,进而
相关推荐
-
鼎帷咨询2025年DeepSeek战略创新分析报告-围绕DeepSeek尖刀点加速打造AI产业刀锋链39页

 2025-05-13 19940
2025-05-13 19940 -
新战略咨询2024移动机器人AGV_AMR专用激光雷达产品发展蓝皮书31页
 2025-05-15 19947
2025-05-15 19947 -
甲子光年2025年DeepSeeK开启AI算法变革元年报告16页
 2025-05-13 19955
2025-05-13 19955 -
CyberRobo2024全球人形机器人产品数据库报告-人形机器人洞察研究BTIResearch99页
 2025-05-15 17948
2025-05-15 17948 -
少年商学院2025年DeepSeek中小学生使用手册81页
 2025-05-13 19839
2025-05-13 19839 -
英普利集团2025企业出海白皮书中东篇精编版39页
 2025-05-14 19541
2025-05-14 19541 -
曼昆律所2024年Web3.0区块链项目出海法律白皮书71页
 2025-05-14 18533
2025-05-14 18533 -
火山引擎2024火山引擎视频云实践精选集224页
 2025-05-15 18939
2025-05-15 18939 -
2025年无人机生态系统发展计划报告(英文版)-世界银行
 2025-06-05 472
2025-06-05 472 -
2025Q1中国企业创投[CVC]发展报告
 2025-06-05 307
2025-06-05 307
相关内容
-
甲子光年2025年DeepSeeK开启AI算法变革元年报告16页
分类:机构报告
时间:2025-05-13
标签:
格式:PDF
-
新战略咨询2024移动机器人AGV_AMR专用激光雷达产品发展蓝皮书31页
分类:机构报告
时间:2025-05-15
标签:
格式:PDF
-
鼎帷咨询2025年DeepSeek战略创新分析报告-围绕DeepSeek尖刀点加速打造AI产业刀锋链39页
分类:机构报告
时间:2025-05-13
标签:
格式:PDF
-
少年商学院2025年DeepSeek中小学生使用手册81页
分类:机构报告
时间:2025-05-13
标签:
格式:PDF
-
英普利集团2025企业出海白皮书中东篇精编版39页
分类:机构报告
时间:2025-05-14
标签:
格式:PDF
-
火山引擎2024火山引擎视频云实践精选集224页
分类:机构报告
时间:2025-05-15
标签:
格式:PDF
-
曼昆律所2024年Web3.0区块链项目出海法律白皮书71页
分类:机构报告
时间:2025-05-14
标签:
格式:PDF
-
CyberRobo2024全球人形机器人产品数据库报告-人形机器人洞察研究BTIResearch99页
分类:机构报告
时间:2025-05-15
标签:
格式:PDF
-

中国购车用户家庭存款洞察报告 (2025版)
分类:
时间:2025-07-11
标签:
格式:PDF
-

2025中国低空经济市场现状报告
分类:
时间:2025-07-11
标签:
格式:PDF



