大语言模型高效自动对齐

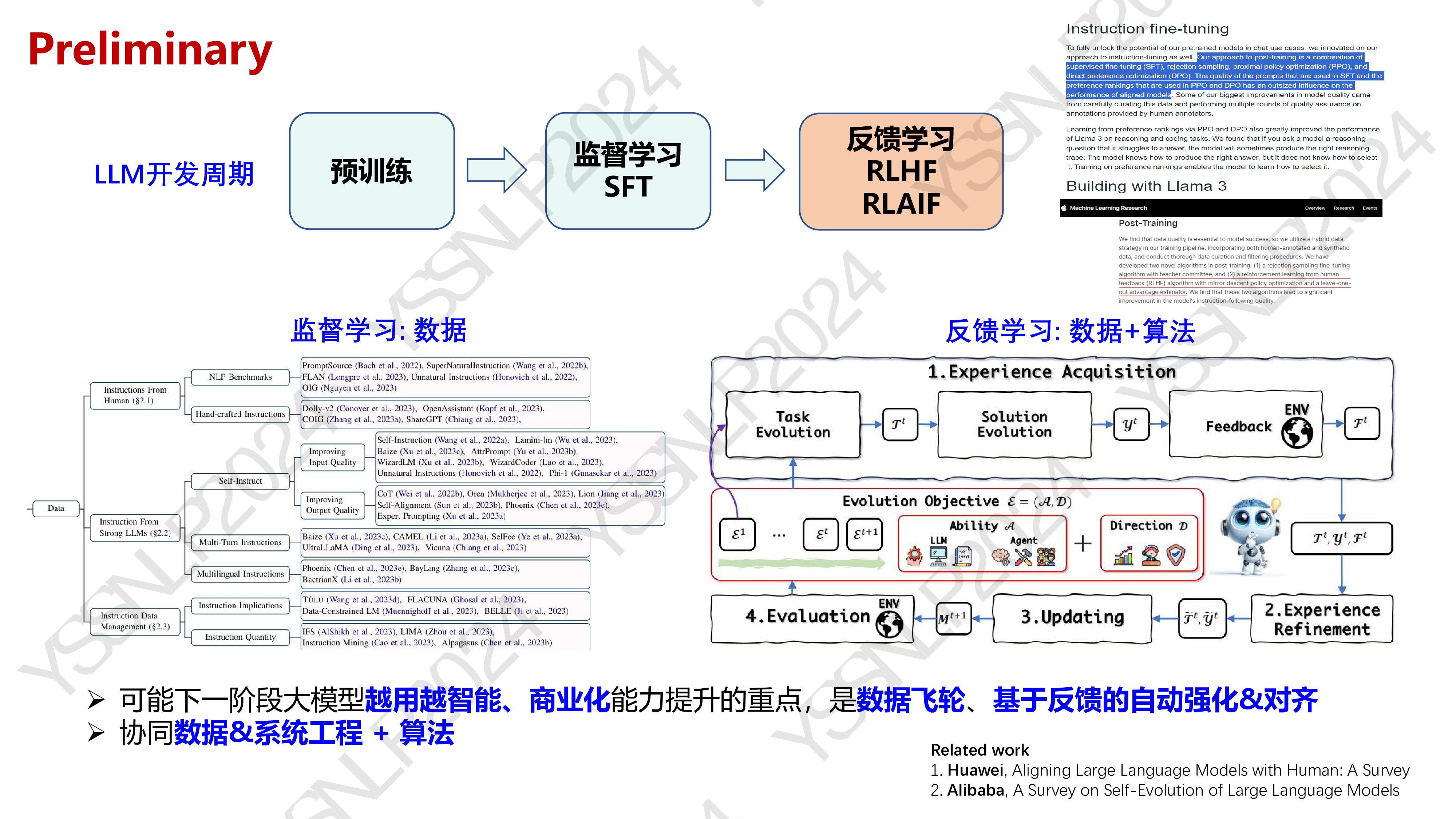


大语言模型高效自动对齐基于反馈学习的模型能力自动强化演进糜飞华为-诺亚方舟实验室-语音语义【盘古大模型研发研究员】YSSNLP2024YSSNLP2024YSSNLP2024YSSNLP2024YSSNLP2024YSSNLP2024YSSNLP2024YSSNLP2024YSSNLP2024Ø可能下一阶段大模型越用越智能、商业化能力提升的重点,是数据飞轮、基于反馈的自动强化&对齐Ø协同数据&系统工程 + 算法Related work1. Huawei, Aligning Large Language Models with Human: A Survey2. Alibaba, A Survey on Self-Evolution of Large Language Models监督学习: 数据反馈学习: 数据+算法预训练监督学习SFT反馈学习RLHFRLAIFLLM开发周期PreliminaryYSSNLP2024YSSNLP2024YSSNLP2024YSSNLP2024YSSNLP2024YSSNLP2024YSSNLP2024YSSNLP2024YSSNLP2024lOpenAI投入20%的计算资源在超级对齐研究上,由Ilya Sutskever和Jan Leike共同领导(Anthropic)Pillar 1: 在人类可以直接评估的任务上如何与人类对齐RLHFSFTPillar 2: 在人类难以直接评估的任务上,辅助AI高效对齐(Scalable Oversight)3. AI反馈对齐(细粒度强化)1. AI问题自动发现(突破难例发现效率)2. AI辅助反馈(高质量反馈)OpenAI超级对齐背景:分阶段实现强智能体的安全可控、自动对齐人工反馈AI辅助人工对齐(超级对齐初级阶段)AI辅助AI对齐(终极超级对齐)Step1Step 3Step 2•(OpenAI) 过程反馈:稠密过程奖励模型,提升数学推理精度10%•(OpenAI) 过程对齐:利用过程奖励模型,分步骤打分强化学习训练,精度提升6%•(Apple、Google、Llama、Qwen):多阶段/在线强化学习,显著提升模型性能•(Google) 工具反馈:拆解规划并使用工具校验,提升高阶推理精度20%•(Google) 自动化红队:构建自动攻击红队模型,提升问题空间难例发现效率3倍•(Google)
相关推荐
-
鼎帷咨询2025年DeepSeek战略创新分析报告-围绕DeepSeek尖刀点加速打造AI产业刀锋链39页

 2025-05-13 19936
2025-05-13 19936 -
新战略咨询2024移动机器人AGV_AMR专用激光雷达产品发展蓝皮书31页
 2025-05-15 19943
2025-05-15 19943 -
甲子光年2025年DeepSeeK开启AI算法变革元年报告16页
 2025-05-13 19950
2025-05-13 19950 -
CyberRobo2024全球人形机器人产品数据库报告-人形机器人洞察研究BTIResearch99页
 2025-05-15 17939
2025-05-15 17939 -
少年商学院2025年DeepSeek中小学生使用手册81页
 2025-05-13 19833
2025-05-13 19833 -
英普利集团2025企业出海白皮书中东篇精编版39页
 2025-05-14 19537
2025-05-14 19537 -
曼昆律所2024年Web3.0区块链项目出海法律白皮书71页
 2025-05-14 18531
2025-05-14 18531 -
火山引擎2024火山引擎视频云实践精选集224页
 2025-05-15 18933
2025-05-15 18933 -
2025年无人机生态系统发展计划报告(英文版)-世界银行
 2025-06-05 465
2025-06-05 465 -
2025Q1中国企业创投[CVC]发展报告
 2025-06-05 301
2025-06-05 301
相关内容
-
甲子光年2025年DeepSeeK开启AI算法变革元年报告16页
分类:机构报告
时间:2025-05-13
标签:
格式:PDF
-
新战略咨询2024移动机器人AGV_AMR专用激光雷达产品发展蓝皮书31页
分类:机构报告
时间:2025-05-15
标签:
格式:PDF
-
鼎帷咨询2025年DeepSeek战略创新分析报告-围绕DeepSeek尖刀点加速打造AI产业刀锋链39页
分类:机构报告
时间:2025-05-13
标签:
格式:PDF
-
少年商学院2025年DeepSeek中小学生使用手册81页
分类:机构报告
时间:2025-05-13
标签:
格式:PDF
-
英普利集团2025企业出海白皮书中东篇精编版39页
分类:机构报告
时间:2025-05-14
标签:
格式:PDF
-
火山引擎2024火山引擎视频云实践精选集224页
分类:机构报告
时间:2025-05-15
标签:
格式:PDF
-
曼昆律所2024年Web3.0区块链项目出海法律白皮书71页
分类:机构报告
时间:2025-05-14
标签:
格式:PDF
-
CyberRobo2024全球人形机器人产品数据库报告-人形机器人洞察研究BTIResearch99页
分类:机构报告
时间:2025-05-15
标签:
格式:PDF
-

2025泡泡玛特POP MART品牌手册
分类:
时间:2025-06-21
标签:
格式:PDF
-

利用人工智能技术全面应对电子邮件威胁
分类:
时间:2025-06-21
标签:
格式:PDF



